My Experience Writing Java Backend Microservices at WePay
I wanted to share some of the things I've learned from writing over 10 Java microservices at WePay.
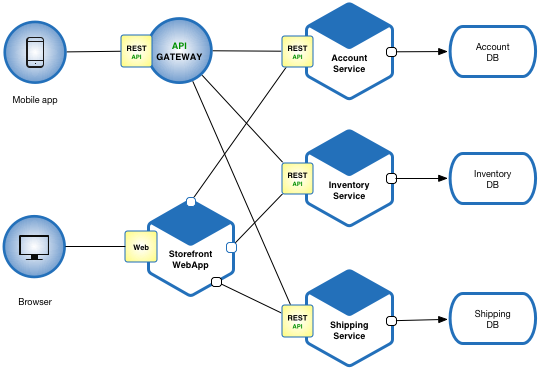
Last week I wrote a blog post reflecting on my first year at WePay. One of the sections touched on how I learned to build microservices, and I wanted to dive deeper into what it has been like creating and maintaining microservices on my team at WePay.
An Example of a Monolithic Repository
5 or 10 years ago, most company codebases were monolithic, "mono" meaning one. There was generally only one repository in which all comnits and pull requests were based off of. While it was easy to call helper functions and work with all code in one place, having a monolithic architecture also made it slower to build and test code, to roll back changes, and to scale certain services. Moreover, all teams would more or less need to develop with the same coding language.
My experience at my first job was with a monolithic repository. We had all of our code in this monolith: robot algorithmic code, robot controls code, Ansible robot computer setup code, React JavaScript code, robot Flask app code to serve info to the frontend, and much more. I remember that this monolithic architecture made it difficult to ensure compatibility of our UI version and backend server versions. For instance, when we would deploy a robot into the field we would deploy a certain version of the monolith. This meant that if there was a bug in the React UI that we discovered out on the field, we couldn't just patch it and deploy it because doing so would require re-deploying the entire monolith. Vice versa, if there was a problem on the Flask backend server which served information to the UI, it was not trivial to make a quick fix to the backend.
If I was the designer of that repo, I would have separated out different repositories for the UI, the Flask server, the robot code, Ansible, and more. Would separating out the monolith in this way mean we would have a microservice architecture? I would argue no because this type of separation would still only be at the product level: a backend repo, a frontend repo, a robot repo. Making something into a microservice would involve separating out a product into multiple services, such as separating a robot Flask backend into multiple services: a service that serves robot actions, another that serves robot visualizations, another that serves robot locations, etc.
My Experience Writing Microservices at WePay
Over the past year, I have gained a lot of experience writing microservices at WePay. The WePay software engineering organization is especially strong at microservices and system design architecture of microservices because WePay's product is a distributed system that exposes API's to handle credit card payments. Because WePay's backend is distributed and runs entirely in Google Cloud, it runs off of lots of microservices. The DevOps and DevTools teams have also done an exceptional job of writing a suite of tools that make it easy to manage the microservice lifecycle. There are tools to generate boilerplate code for a new microservice, tools to create a new Kubernetes pod for a microservice, tools to deploy new iterations of the microservices, tools to handle Kibana logging, tools to get the health of a microservice, tools to get the buildinfo of a microservice, and much more.
This amazing infrastructure for developers to write microservices is a large reason why I have been able to help expand my team's projects from 2 to over 10 microservices. Without exposing exactly the microservices that I have written since that is company proprietary information, I'd like to share an idea of how the microsystem architecture looks like behind the scenes for one of our apps.
Some of our other apps have even more complicated microservices, or have more scheduling.
Writing Design Documents
Every Enterprise Engineering service/app I have written has had a detailed design doc (15 - 20 pages on average) before any code was written. The design doc generally focuses on one particular microservice, even though the application we build may call other existing microservices or may even require us to create a new microservice.
Naturally, I think that I have become quite experienced in writing design docs and I have actually received many compliments from my teammates, manager, and manager's manager about how in-depth my design docs go. After around 2 weeks or so planning meetings to scope out requirements, writing the design doc, and soliciting feedback, I write the microservice and also update the design doc if things are changed during development (which is almost always the case since it is nearly impossible to plan everything out). After the microservice is deployed, the design doc becomes my template for writing a finalized Confluence design doc in our team's workspace. The process of writing the finalized design doc typically only takes me half a day to a day - which is very fast relatively speaking - because all of the work had been done in the design doc phase prior to writing out the code.
An Annoyance: Redundancy in Microservices
I wish I could say that writing microservices is all rainbows and unicorns, but in reality there are always tradeoffs between different software architectures. Earlier I detailed some of the benefits of microservices, and this article would not be complete without acknowledging some of the drawbacks and annoyances of writing microservices.
One of my biggest annoyances with writing microservices is the amount of duplicate boilerplate code shared by microservices. Most of our microservices have the same components: HTTP endpoints, JWT authentication, a CloudSQL database, maybe a Redis cache, an HTTP client which makes the HTTP requests, logging, exception handling, and much more. Luckily, our DevOps and DevTools teams have created amazing developer tools which automatically generate the Java Dropwizard and Python Falcon web frameworks. However they do not cover everything. One of the things that generated boilerplate code does not cover is customized exception types that can handle exceptions specific to each app. I've found myself writing a similar exception class for each project. Another thing that generated code does not cover is the configuration of notifications. Our services can log to Kibana or send notifications to Slack or to email, and the recipients of these messages needs to be configured in a Java constant file. We have extrapolated some of the notifications shared code into a utils Java library to reduce code duplication, but there are parts that cannot be moved into a library because they are microservice-specific.
Besides code, there are also certain files that can be redundant between microservices. One example of such files are the truststore and keystore files, which contain a list of SSL certificates so that the microservice can make network requests. The generated code template does a great job of auto-populating the keystore and truststore files with some WePay certificates, but there are always some team-specific SSL certificates that I need to add every time I set up a repository.
Java Dropwizard
Most of the microservices I have written have been using the Java Dropwizard framework. I felt like it took me around 3 months to understand the structure of the framework well, and now that I understand it I really like it. I like how Dropwizard is structured, has a lot of great libraries built in such as authentication for endpoints and Jersey for web services, and more.
I like how it has a build.gradle file which makes it easy to configure internal and external libraries that we want to add. I like how it has a .yml configuration file which makes it easy to set up configurations for the microservice.
If I was building some new company or non-WePay distributed system, I would use Java Dropwizard.
Conclusion
In conclusion, I have learned a lot about developing microservices during my first year at WePay. I feel like there is still so much more to learn. For instance, just today I was discussing with my teammate about adding websockets to our microservice since one of our applications requires real-time form updates since the app is used in real-time.



